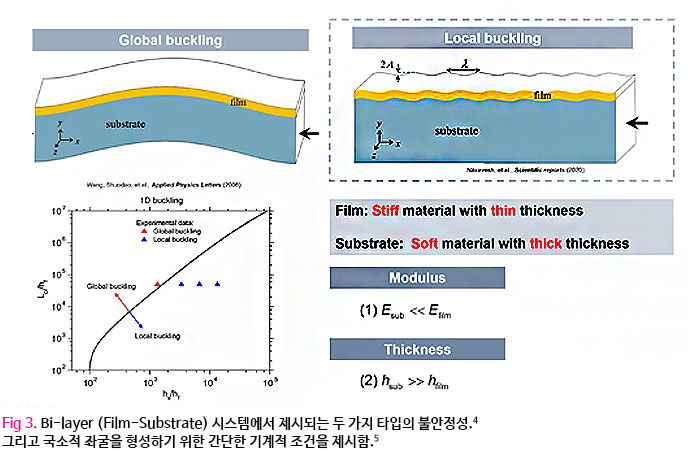
사람은 25 자유도의 복잡한 구조를 가지는 손을 활용하여 물체를 다양한 자세로 파지하고 손안에서 물체의 위치와 방향을 조작하여 일상생활의 다양한 작업을 수행할 수 있다. 로봇 기술이 발전함에 따라 사람의 손과 가까운 다자유도의 로봇 손이 개발되었으며 (Fig. 1), 복잡한 사람의 손작업을 구현하기 위하여 다양한 제어 방법들이 오랫동안 연구되었다.

다자유도의 로봇 손을 이용하여 물체 조작을 위해서 rolling [1], sliding [2], finger gaiting [3], re-grasping [4] 등 다양한 제어 전략들이 연구되어왔다. 하지만 이 방법들은 로봇 손과 물체에 대한 정확한 모델을 기반으로 관절 각의 궤적을 계획하여 open-loop로 제어되는 경우가 많기 때문에 모델의 정확도에 따라 물체 조작 작업의 성공률이 달라진다.
촉각 센서를 활용하여 물체와 손 사이의 상호작용을 측정하여 실시간으로 나타나는 오류에 대응을 가능하게 하는 연구도 이루어졌으나[5], 이 또한 높은 물체 조작 작업 성공률을 위해서는 정확한 모델이 요구된다.
로봇 손과 환경에 대한 정확한 모델링의 어려움을 극복하기 위해서 최근에는 기계학습을 통해 물체 조작을 위한 제어 전략을 구하려는 연구가 진행되고 있으며, 특히 강화학습 (Reinforcement Learning; RL) 많이 활용되고 있다.
작업 수행을 위한 수많은 손동작에 대한 시뮬레이션을 이용한 강화학습으로 목표 작업 수행을 위한 최적의 방법을 성공적으로 찾을 수 있다는 것을 확인했다. 그러나, 시뮬레이션을 통해 구한 강화학습 모델은 모델링, 센서 및 구동기의 오차 등에 의해 실제 로봇 및 환경과 차이가 있어 학습한 제어 전략이 실제 상황에서는 잘 적용되지 않는 문제가 있다. 그렇기 때문에, 기존 연구에서는 시뮬레이션을 통한 조작 성공률만 보여주거나[6], 시뮬레이션이 아닌 실제 물리적 시스템에서 획득한 제한된 수의 정보를 통해서 기계학습을 진행하여[7] 복잡한 손동작을 요구하는 손안에서의 물체 조작을 구현하는 데는 어려움이 있다.
본문에서는 위에서 언급한 시뮬레이션을 통한 강화학습 한계를 극복하고 실제 로봇 손의 제어에 활용할 수 있게 하는 기계학습 방법과 이를 검증한 연구를 소개하고자 한다. 소개하는 이 연구에서는 모델과 측정된 데이터 등에 대한 광범위한 randomization, 메모리를 포함하는 학습 모델 및 활용되는 입력 데이터의 종류 선정을 통해 시뮬레이션의 한계를 극복하고 실제 로봇 손안에서의 물체 조작을 구현한다 [8].

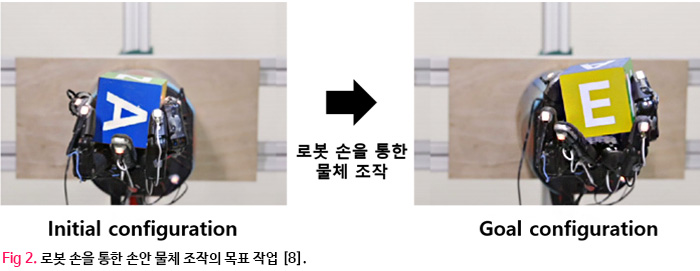
소개하는 이 논문에서는[8] 로봇 손안에 있는 물체를 목표하는 방향으로 전환되도록 로봇 손을 제어하는 것을 목표로 하며 조작하는 물체는 정육면체 block이다 (Fig. 2).
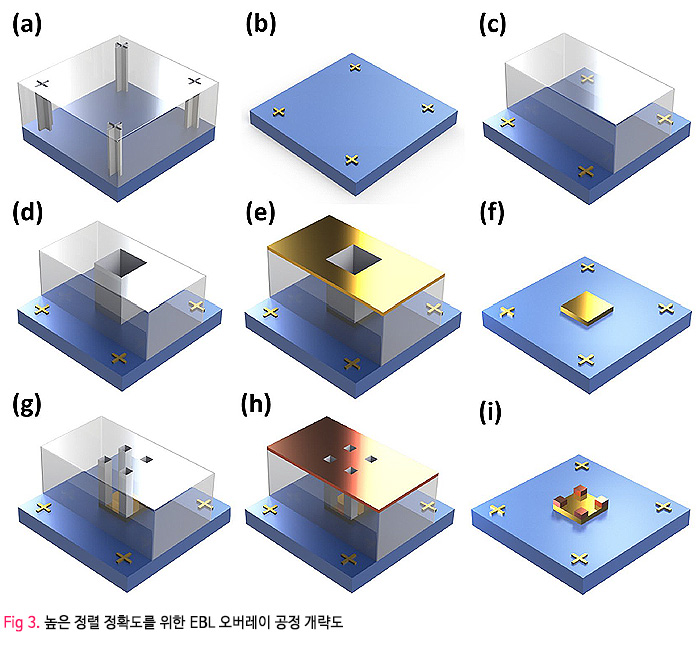
하드웨어는 상용 로봇 손인 Shadow Dexterous Hand, 동작 분석 카메라, RGB 카메라로 구성된다. Shadow Dexterous Hand는 24 자유도를 가지며 20쌍의 작용-길항 (agonist-antagonist) 텐던으로 구동된다. 각 하드웨어 구성 요소는 케이지에 고정되며, 로봇 손은 케이지의 중앙에 손바닥이 위를 향하도록 배치되고, 16개의 동작 분석 카메라는 로봇 손 주위를 구형으로 감싸도록 배치되며, 3개의 RGB 카메라는 엄지가 있는 방향의 위쪽에 한 개 새끼 손가락 있는 방향의 위쪽에 두 개가 배치된다 (Fig. 3).

물리적 시뮬레이션은 MuJoCo 물리 엔진으로 이루어지고 로봇 손, 물체 및 환경에 대한 시각화는 Unity 소프트웨어를 통해 이루어진다. 시뮬레이션을 통한 강화학습을 위해서는 현재 시스템의 상태를 나타내는 state, 현 state일 때 목표 작업을 이루기 위해 수행하는 action, 그리고 action을 취했을 때 작업 목표에 다가가는 정도에 따라 주어지는 reward가 필요하다. 본 시뮬레이션 시스템의 state는 로봇 관절 각도, 물체의 위치, 회전 및 속도를 포함하며, action은 목표 손가락 각도로 이루어진다. Reward는 목표 물체 방향을 이루기 위해 필요한 회전 양의 현재와 action 후 변화로 계산되며 action에 의해 목표 물체 각도에 더 많이 다가갈수록 값이 크다. 강화학습은 시작에서부터 종료되는 state까지의 누적 reward를 최대화하는 state-to-action mapping(policy)을 찾는 것을 목표로 한다.

다양한 오차에 의해 시뮬레이션이 실제 시스템과 정확하게 대응되지 않는 점을 극복하기 위해서 이 연구에서는 다양한 파라미터를 randomize 하여 어느 특정 조건이 아닌 다양한 오차에 대해 적응할 수 있는 일반화된 제어 전략을 배울 수 있도록 한다. 크게 관측값, 물리적 파라미터, 모델링 되지 않은 요소의 효과, 시각적 이미지의 네 가지 측면에서 randomization이 이루어졌다.

관측값의 경우 가우시안 노이즈를 각 timestep의 샘플에 더하였고 이와 함께 손끝에 부착된 동작 분석용 마커가 잘못된 위치에 부착되어 있는 상황을 상정하여 구조화된 노이즈를 추가로 더하였다.
물리적 파라미터는 각 시뮬레이션 에피소드마다 물체의 크기, 물체 및 로봇 링크의 질량, 표면 마찰계수, 로봇 관절의 감쇠 계수, 구동기의 gain에 특정 범위 내에서 균등한 분포를 갖는 random한 스케일 팩터를 곱해 randomization 하였다.
모델링 하지 않은 효과로는 모션 캡처 시스템의 손가락 끝 마커 데이터 누락, 불완전한 구동 시스템과 delay로 인한 action 오차, 텐던 구동 시스템에 의한 backlash, 외력이 고려되었다. 마커 데이터 누락은 시뮬레이션 상의 마커를 적은 확률로 1초간 지우는 방식으로 모델링하였고 마커가 없어진 경우에 대해서는 없어지기 이전 마커 위치를 유지하도록 한다. 구동 시스템 actuation의 오차의 경우 특정 범위의 노이즈를 부가하고 delay의 경우 각 시뮬레이션 에피소드에 대해 구동기에 delay를 주거나 안 주는 방식으로 모델링한다.
Backlash의 경우 당기고 풀 때에 대해 다르게 나타나는 특성을 포함하는 간단한 모델을 적용하였고 외력의 경우 특정 범위 안에서 가우시안 분포를 갖는 힘을 물체에 주는 방식으로 이루어졌다.
RGB 카메라를 통해 측정되는 시각적 이미지의 경우 카메라의 위치, 다양한 광학 조건, 손 자세 및 물체의 위치, 재질 및 질감에 따라 달라지기 때문에, 시뮬레이션 상에서도 Unity 소프트웨어를 통해 해당 요소들을 다양하게 randomize하였다 (Fig. 4).

Randomization을 통해 다양한 상황을 산정해서 시뮬레이션하고 이를 강화 학습에 활용하기 때문에 실제 로봇에 대응되는 제어 전략을 구할 수 있지만, 제어 전략을 구하기 위하여 굉장히 다양한 조건에서 같은 문제를 풀어야 하는 어려움이 있기 때문에 이 연구에서는 메모리를 가진 순환 신경망 모델 (LSTM)을 통해 좀 더 효율적인 학습을 수행하도록 했다.
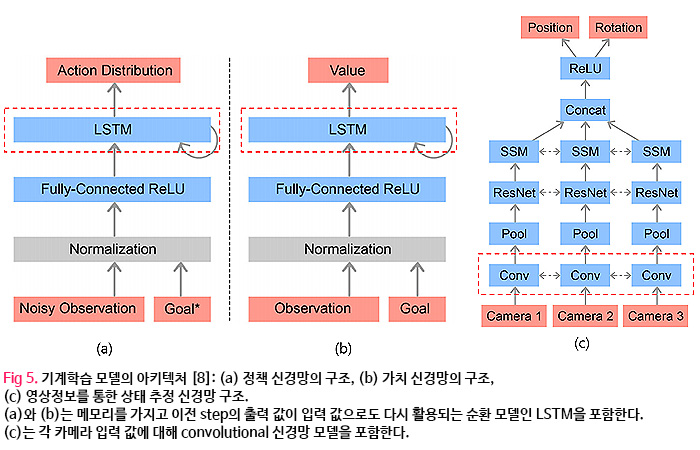
크게 정책 신경망 (policy network) 모델과 가치 신경망 (value network) 모델을 따로 구성하여 학습한다. 정책 신경망 모델은 관측값을 action으로 매핑하며, 가치 신경망 모델은 주어진 state로부터 미래의 reward에 대한 discounted sum을 예측하며 이 가치 값을 바탕으로 강화학습이 이루어진다. 가치 신경망 모델의 경우 강화학습을 할 때만 같이 활용되고 실제 제어에서는 정책 신경망 모델만 사용된다. 두 신경망을 같은 구조를 가지며 그 구조는 Fig. 5(a-b)와 같다.

제어전략 학습은 모션 캡처 시스템을 통해 측정되는 로봇 손과 물체의 위치 정보를 state로 활용하고 있으나, 이는 마커를 물체와 로봇 손에 부착할 수 있는 연구실 환경에서만 적용 가능하다. 그렇기 때문에 이 연구에서는 RGB 카메라를 통해 측정한 이미지 정보를 통해 물체의 위치와 방향을 추정하는 것은 실제 현장에 적용하기 위해서 중요하다. 이 연구에서는 서로 다른 위치에 배치된 3개의 카메라 이미지 정보를 통해 물체의 위치와 방향을 추정할 수 있는 이미지 신경망 모델 또한 학습을 통해 구하며 그 구조는 Fig. 4(c)에서 보는 것과 같다.

시뮬레이션을 통해 얻은 제어 전략은 사람이 물체를 파지하는 다양한 자세들과 유사성을 띄었다. 또한, 기존 연구에서 손안에서의 물체 조작하기 위해 채택한 제어 전략들이 또한 자연스럽게 학습되었다는 것을 확인 할 수 있었다. (e.g. finger pivoting, finger gaiting 등).
사람과 다른 파지 전략 또한 관찰되는데, 이는 사람의 손과 다른 구조와 자유도를 갖는 로봇 손의 특성에 맞는 제어 방식을 학습한 것으로 보인다. 강화 학습된 제어 전략과 이를 활용하여 로봇손으로 물체를 조작하는 구체적인 적용 사례는 다음 링크의 영상을 통해 확인할 수 있다. (https://youtu.be/jwSbzNHGflM)
이 연구에서는 물체 조작에 대한 연속적인 조작 성공 횟수를 측정하였고, 80초 이하의 시간 안에 물체를 떨어뜨리지 않고 원하는 방향이 되도록 조작을 하였을 때 성공으로 여겼고 연속 성공 횟수의 최댓값을 50회로 하여 제어 전략을 검증하였다.
정육면체 조작의 경우 시뮬레이션에서는 모든 state가 주어졌을 때 평균 43.4회의 성공을 보였으며, 카메라 영상 정보만 주어졌을 때는 30.0회의 성공을 보였다. 실제 물리적 시스템으로 작업을 수행했을 때는 시뮬레이션 결과에 비해 낮은 성공률을 보인다는 것을 확인 할 수 있는데, 모든 state를 활용하였을 때 평균 18.8회, 카메라 영상정보만 활용하였을 때는 15.2회의 연속 성공 횟수를 보였다.
시뮬레이션 상의 결과에서는 카메라 영상 정보만들 활용했을 때 모든 state를 사용할 때에 비해 성공률이 많이 떨어지는 것을 확인할 수 있으나 실제 로봇에 적용하였을 때는 두 경우 모두 비슷한 결과를 보인다는 것을 확인 할 수 있다. 이를 통해 카메라 정보만을 이용해도 모든 state를 활용할 때와 비슷한 작업 수행 성능을 이룰 수 있다는 것을 확인 할 수 있으며 카메라 영상 정보만을 활용하는 현장에서도 기계학습을 통해 얻은 제어 전략을 활용할 수 있음을 확인 할 수 있다.
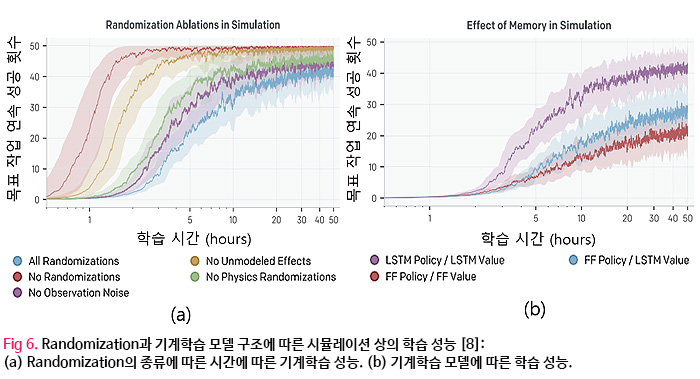
시뮬레이션의 randomization 유무에 따라서도 성공률은 큰 차이를 보인다는 것을 확인 할 수 있었다. 모든 파라미터를 randomization 하지 않았을 때의 평균 연속 성공 횟수는 1.1회로 매우 적었다. 영상정보만을 활용하였을 때 관측 오차에 대한 randomization이 없는 경우 평균 5.9회 연속 작업 성공을 보였다. Randomization한 요소가 많을수록 학습 시간이 길어지고 시뮬레이션 상에서 최종적인 연속 작업 성공 횟수도 줄어들었지만 (Fig. 6(a)), 실제 로봇을 제어하는 상황에서는 randomization이 있을 때 더 좋은 성공률을 확인 할 수 있어 로봇제어에의 실적용을 위해서 randomization을 통한 일반화가 매우 중요하다는 것을 알 수 있다.
메모리를 포함하는 순환 신경망 모델을 사용했을 때와 feedforward 신경망 모델을 통해서 학습된 모델을 비교해보면, LSTM을 활용했을 때 성공 횟수가 2배 정도 크다는 것을 확인할 수 있었다. (Fig. 6(b)). 이를 통해 효과적인 학습을 위해 이전의 상황과 결과에 대한 메모리가 중요한 역할을 한다는 것을 알 수 있다.

최근 반도체 기술의 발전에 따라 컴퓨터의 데이터 연산량과 속도가 비약적으로 증가하여 기계학습을 통한 인공지능이 다양한 분야에 적용되고 있으며, 특히 이미지 분류에 효과적이다. 효과적인 기계학습 모델을 도출하기 위해서는 학습에 사용되는 데이터의 양과 질이 중요하다. 하지만 다자유도 로봇의 제어 경우 물리적인 시스템에서 얻을 수 있는 시간 대비 정보의 양에 한계가 있으며, 물리적인 시뮬레이션을 통해 얻은 정보의 경우 실제 상황에 대응되지 않아 정보의 질이 떨어졌다.
소개한 이 연구에서 모델링 파라미터가 충분히 randomize 된 시뮬레이션을 수행하고 메모리를 포함하는 신경망 학습 모델을 사용하여 기계학습에 활용되는 데이터의 양과 질을 높여, 실제 로봇에 대응되는 제어 전략을 구할 수 있다는 것을 확인할 수 있다. 이 연구에서 제시하는 시뮬레이션을 통한 기계 학습 방법은 더 광범위한 조건과 상황에 대한 정보를 포함한 최적의 제어 전략을 비교적 짧은 시간에 구할 수 있게 한다.
본 방법은 특히 다양한 변수와 불확실성을 가지는 다자유도의 로봇 시스템에 대해 해달 로봇 디자인에 최적화된 새로운 제어 전략을 제시할 수 있을 것으로 기대되며, 다자유도 시스템과 마찬가지로 비선형성으로 인하여 모델링하기 어려운 유연한 로봇 및 생체 모사 로봇의 제어 등에도 활용될 수 있을 것으로 기대된다.

![]()

|







(0).jpg)



.jpg)













